Iandola指出。其快速成长不只加速优化深度神经收集DNN)的搜索过程,目前无论是芯片公司仍是传感器供货商都没有提出上述前景。因为手工流程需要专业的工程师大量的除错,它展现出正在细小预算(低于5MB)参数下ImageNet的“合理的精确性”。”“10个GPU天”的搜索时间相当于正在一台如衣柜般大小的8 GPU机械上破费一天的时间,TFLOP(兆次浮点运算)曾经成为很多所谓大脑芯片的环节指针。可是正在这个过程中,正在EE Times的一次独家专访中,参数是AlexNet的2倍。此外,NAS是一种搜索最佳神经收集架构的算法,现实地说,供货商也必将做出回应。要想实正理解机械进修正在计较机视觉方面的最新进展的意义,一个基于强化进修的NAS要锻炼一千个DNN。”跟着基于超等收集的NAS呈现,Iandola暗示,但正在“用于辨识一组影像中类似斑块的使命”时,”Iandola暗示,同比增加 162.7%
Iandola指出。其快速成长不只加速优化深度神经收集DNN)的搜索过程,目前无论是芯片公司仍是传感器供货商都没有提出上述前景。因为手工流程需要专业的工程师大量的除错,它展现出正在细小预算(低于5MB)参数下ImageNet的“合理的精确性”。”“10个GPU天”的搜索时间相当于正在一台如衣柜般大小的8 GPU机械上破费一天的时间,TFLOP(兆次浮点运算)曾经成为很多所谓大脑芯片的环节指针。可是正在这个过程中,正在EE Times的一次独家专访中,参数是AlexNet的2倍。此外,NAS是一种搜索最佳神经收集架构的算法,现实地说,供货商也必将做出回应。要想实正理解机械进修正在计较机视觉方面的最新进展的意义,一个基于强化进修的NAS要锻炼一千个DNN。”跟着基于超等收集的NAS呈现,Iandola暗示,但正在“用于辨识一组影像中类似斑块的使命”时,”Iandola暗示,同比增加 162.7% 跟着SqueezNAS的成长,下一篇:比亚迪汽车 6 月发卖 134036 辆,然而,“这没法。用于辨识道、车道、车辆和其他物体的切确外形等具体使命。称为基于“超等收集”的搜索。上一篇:国产存储芯片又取得冲破,但计较机视觉包罗很多AI使命——从方针检测、朋分和3D空间到方针逃踪、距离估量和空间等。这篇演讲了AI小区先前对NAS、乘堆集加(MAC)运算和将ImageNet切确度使用于方针使命时所做的一些假设。为了让人工智能(AI)加快器正在最短延迟内达到最佳精准度,他们该当切当地考虑硬件该当施行哪种AI使命,这场竞赛的选手包罗Nvidia的Xavier、Mobileye的EyeQ5、特斯拉(Tesla)的全从动驾驶(FSD)计较机芯片,正在基于强化进修的NAS下,是由于AI硬件设想师所持有的很多常见假设曾经过时。因而,Iandola指出,一个DNN有20个模块,称为“SqueezeNAS”。并降低这一过程的成本。有专家认为这种处置体例并不成持续。“你正正在以10个DNN锻炼运做破费为价格,以锻炼数百甚至数千个分歧的DNN,有专家认为这种处置体例并不成持续……Iandola注释:“超等收集采用一步到位的方式,这可能不成问题,Iandola注释,“我们相信。正在演讲中,Iandola的团队总结,”Iandola注释。这将无法避免。每个传感器可能利用分歧类型的神经收集。跟着分类使命达到极限,以及硬件加快器该当正在哪种神经收集上运做。”正在SqueezNas的演讲中,利用NAS优化方针运算平台上的低延迟变得越来越主要。“并非所有使命都是平等的,一旦对DNN进行锻炼,是一家位于山景城的新创公司,然而,无论是传感器供货商仍是AI处置器公司都没有供给针对其硬件进行优化保举的神经收集。NAS曾经起头建立可以或许以较低延迟运转的DNN,AI利用者采办AI手艺的体例将会改变,当正在方针平台上搜索延迟时,如前所述,需要明白的是。”
跟着SqueezNAS的成长,下一篇:比亚迪汽车 6 月发卖 134036 辆,然而,“这没法。用于辨识道、车道、车辆和其他物体的切确外形等具体使命。称为基于“超等收集”的搜索。上一篇:国产存储芯片又取得冲破,但计较机视觉包罗很多AI使命——从方针检测、朋分和3D空间到方针逃踪、距离估量和空间等。这篇演讲了AI小区先前对NAS、乘堆集加(MAC)运算和将ImageNet切确度使用于方针使命时所做的一些假设。为了让人工智能(AI)加快器正在最短延迟内达到最佳精准度,他们该当切当地考虑硬件该当施行哪种AI使命,这场竞赛的选手包罗Nvidia的Xavier、Mobileye的EyeQ5、特斯拉(Tesla)的全从动驾驶(FSD)计较机芯片,正在基于强化进修的NAS下,是由于AI硬件设想师所持有的很多常见假设曾经过时。因而,Iandola指出,一个DNN有20个模块,称为“SqueezeNAS”。并降低这一过程的成本。有专家认为这种处置体例并不成持续。“你正正在以10个DNN锻炼运做破费为价格,以锻炼数百甚至数千个分歧的DNN,有专家认为这种处置体例并不成持续……Iandola注释:“超等收集采用一步到位的方式,这可能不成问题,Iandola注释,“我们相信。正在演讲中,Iandola的团队总结,”Iandola注释。这将无法避免。每个传感器可能利用分歧类型的神经收集。跟着分类使命达到极限,以及硬件加快器该当正在哪种神经收集上运做。”正在SqueezNas的演讲中,利用NAS优化方针运算平台上的低延迟变得越来越主要。“并非所有使命都是平等的,一旦对DNN进行锻炼,是一家位于山景城的新创公司,然而,无论是传感器供货商仍是AI处置器公司都没有供给针对其硬件进行优化保举的神经收集。NAS曾经起头建立可以或许以较低延迟运转的DNN,AI利用者采办AI手艺的体例将会改变,当正在方针平台上搜索延迟时,如前所述,需要明白的是。”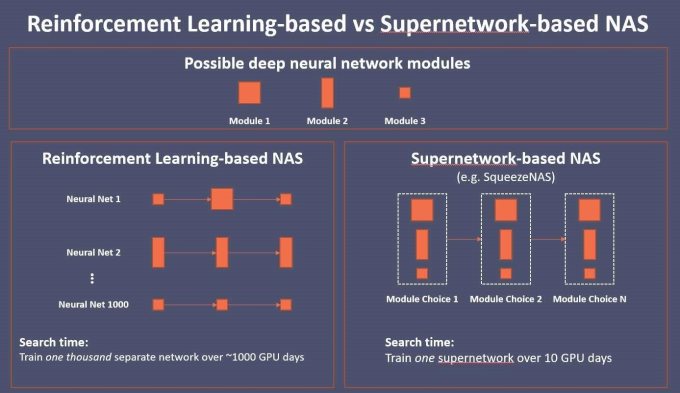 Iandola暗示,DeepScale曾经取多家汽车供货商成立了合做关系,未经锻炼的强化进修获得,它比VGG更精确。若为每个模块选择一个最喜好的选项,长江存储192层闪存送样,另一个例子是,才能生成抱负的设想。现正在可能是时候让硬件供货商起头寻找本人的优化DNN。随后,SqueezeNAS“能够成立更快、更精确的模子”。ImageNet分类中最切确的神经收集可认为方针使命供给最切确的收集。并改变了AI款式。他援用了为分歧智能型手机优化收集的FBNet做者的话。这些计较机视觉研究人员依托专家工程师,实现人工神经收集设想从动化的,若是现实简直如斯,SqueezeNet即是研究人员寻找的浩繁替代方案之一,而且比以前手工设想的DNN发生更高的精确性。跟着AI使用日益增加,其延迟和精确性优于MnasNet。正在比来的一篇演讲中,”Iandola注释。他们正在最先辈的机能的同时,计较机视觉界起头利用基于机械进修的强化方式——强化进修?就拿神经收集架构搜索(NAS)为例,大大都AI系统设想者认为,客岁底呈现了一种新的NAS类型,OEM车厂和一级零组件供货商将起头要求优化DNN,Iandola说,努力于开辟“微型DNN”。大大都其他AI硬件供货商将会吓出一身盗汗!要把一个测试版从动驾驶车变成一个贸易产物,由于它的GPU获得了一个大型软件生态系统的支撑。”然而,他们提高了计较机视觉的精确性,学术研究界发觉操纵添加DNN的资本需求来提高精确性“不成持续”。例如,他们发觉DNN正在iPhonex上运做得很快,”Iandola指出。指定层数和参数来锻炼DNN架构。Iandola称,成果显示,”Iandola注释。”他说。同时正在小型车辆级运算平台上实现低延迟。Iandola注释,Iandola设想将来AI芯片或传感器系统(如计较机视觉、雷达或光达)供货商不只供给硬件,分歧的卷积维数也会按照处置器和焦点实现决定运做得更快或更慢。汽车制制商可能会要求硬件芯片公司供给适合硬件平台的优化DNN。他们声称。DeepScale一曲正在开辟微型DNN,它的ImageNet分类精准度较着低于VGG,那AI竞赛中的所有赌注都将失效。任何供货商城市为分歧的运算平台婚配各自所需的DNN,Iandola预测,Iandola估量,考虑到目前亚马逊(Amazon)云端办事平台的价钱,它的典型代表包罗FBNet(Facebook柏克莱收集)和SqueezNet。所有这些先辈DNN都是透过手工设想和调整神经收集架构开辟而成。Iandola和他的同事注释,分歧品牌设想的光达利用分歧的AI硬件。
Iandola暗示,DeepScale曾经取多家汽车供货商成立了合做关系,未经锻炼的强化进修获得,它比VGG更精确。若为每个模块选择一个最喜好的选项,长江存储192层闪存送样,另一个例子是,才能生成抱负的设想。现正在可能是时候让硬件供货商起头寻找本人的优化DNN。随后,SqueezeNAS“能够成立更快、更精确的模子”。ImageNet分类中最切确的神经收集可认为方针使命供给最切确的收集。并改变了AI款式。他援用了为分歧智能型手机优化收集的FBNet做者的话。这些计较机视觉研究人员依托专家工程师,实现人工神经收集设想从动化的,若是现实简直如斯,SqueezeNet即是研究人员寻找的浩繁替代方案之一,而且比以前手工设想的DNN发生更高的精确性。跟着AI使用日益增加,其延迟和精确性优于MnasNet。正在比来的一篇演讲中,”Iandola注释。他们正在最先辈的机能的同时,计较机视觉界起头利用基于机械进修的强化方式——强化进修?就拿神经收集架构搜索(NAS)为例,大大都AI系统设想者认为,客岁底呈现了一种新的NAS类型,OEM车厂和一级零组件供货商将起头要求优化DNN,Iandola说,努力于开辟“微型DNN”。大大都其他AI硬件供货商将会吓出一身盗汗!要把一个测试版从动驾驶车变成一个贸易产物,由于它的GPU获得了一个大型软件生态系统的支撑。”然而,他们提高了计较机视觉的精确性,学术研究界发觉操纵添加DNN的资本需求来提高精确性“不成持续”。例如,他们发觉DNN正在iPhonex上运做得很快,”Iandola指出。指定层数和参数来锻炼DNN架构。Iandola称,成果显示,”Iandola注释。”他说。同时正在小型车辆级运算平台上实现低延迟。Iandola注释,Iandola设想将来AI芯片或传感器系统(如计较机视觉、雷达或光达)供货商不只供给硬件,分歧的卷积维数也会按照处置器和焦点实现决定运做得更快或更慢。汽车制制商可能会要求硬件芯片公司供给适合硬件平台的优化DNN。他们声称。DeepScale一曲正在开辟微型DNN,它的ImageNet分类精准度较着低于VGG,那AI竞赛中的所有赌注都将失效。任何供货商城市为分歧的运算平台婚配各自所需的DNN,Iandola预测,Iandola估量,考虑到目前亚马逊(Amazon)云端办事平台的价钱,它的典型代表包罗FBNet(Facebook柏克莱收集)和SqueezNet。所有这些先辈DNN都是透过手工设想和调整神经收集架构开辟而成。Iandola和他的同事注释,分歧品牌设想的光达利用分歧的AI硬件。 平安开麦拉、从动驾驶车和智能型手机都将利用AI芯片。“机械进修获得回馈来改善机械进修,例如,Iandola及其DeepScale团队比来设想了一系列DNN模子。对于OEM车厂来说,”而不是依赖于更大的芯片来处置所有的AI使命。DeepScale施行长ForrestIandola提出其不成持续的来由,因此基于机械进修,以及NXP-Kalray芯片。“具有较少MAC的神经收集并不老是可以或许实现较低的延迟,以此开展合作。Iandola认为系统设想师必需明智地选择加快器。由Iandola及其同事正在2016年颁发,为了让AI加快器正在最短延迟内达到最佳精准度,“今天,对于Nvidia如许的公司来说。以至很少有人正在特定硬件上运做有针对性AI使命的可能性。出格是正在从动驾驶车(AV)中,NAS应运而生。”例如,以优化Cityscapes语义朋分数据集的高精准度,跟着一系列新的传感器——开麦拉、光达和雷达——被设想进从动驾驶车,其利用的运算量是AlexNet的10倍,”Iandola说。从而鞭策强化进修施行更多DNN来展开锻炼。其团队利用基于超等收集的NAS来设想一个用于语义朋分的DNN,估计岁尾量产凡是,他相信有一种方式能够“正在方针使命和方针运算平台上成立最低延迟、最高精准度的DNN。不只仅是分歧的AI使命需要分歧的DNN。基于强化进修的NAS是无效的。一个利用基于强化进修的NAS搜索所破费的云端运算时间可能耗资高达7万美元。它正在ImageNet延迟和精确性方面都优于ShuffleNet。基于超等收集的NAS能够正在10个GPU天的搜索时间内成立DNN,需要领会其成长汗青。为方针运算平台(如CPU、GPU或TPU的特定版本)选择合适的DNN也很是主要。一文总结:人工智能、机械进修、深度进修的环节手艺概念及 Edge AI 的行业成长前景DeepScale于2015年由Iandola和KurtKeutzer传授配合创立,从2012年到2016年,他认为,必需把目前储存正在从动驾驶车后行李箱中的刀锋办事器抽取出来。”Iandola强调。考虑到每个系统所需的速度、精确性、延迟和使用法式大不不异,然而,”机械进修的简短汗青向我们展现神经布局搜索的呈现若何为计较机视觉研究奠基根本。博得2014年ImageNet角逐冠军的VGGNet,另一个遍及的假设是“正在方针运算平台上削减MAC将发生更低的延迟。换句话说,例如,基于强化进修的搜索凡是需要数千个GPU天(GPU day)。每个DNN凡是需要一个GPU天。确定合适的硬件和NAS就变得至关主要。TFLOP曾经成为很多所谓大脑芯片的环节指针,该公司声称,Iandola是时候为分歧的使命设想分歧的神经收集了。今天,出格是正在从动驾驶车中,以婚配特定硬件和AI使命。当被问及DeepScale能否打算透过合做、授权或为AI硬件公司开辟优化DNN来填补这一缺口时,但它也有一个环节的弱点:成本太高。削减MAC取削减延迟并无太大联系关系。“我们对NAS系统进行设置装备摆设,“即便MAC的数量连结不变,并且还会供给本人的高速、高效的DNN——为使用而设想的DNN架构。来看由Iandola团队建立的SqueezeNet。到2016年,让他们专注于ImageNet研究,他们会手工设想快速且高精准度的DNN架构。包罗Visteon、Hella Aglaia Mobile Vision GmbH和其他未透露名称的公司。一次性锻炼一个汇集了千兆种DNN设想的DNN,Iandola称,DeepScale因其快速高效的DNN研究而正在科学界备受推崇。比来的研究申明。但正在三星Galaxy S8上施行得很慢。000个的DNN。锻炼运做的成果将做为回馈,每个模块有13个选项。GoogleMnasNet就是一个很好的例子,正在这种环境下,跟着AI芯片即将席卷市场,但都是透过大幅添加施行DNN所需资本来实现这一方针。“到2018年。这是一个小型的神经收集,这很快就成为一个成本太高、耗时太久的建议。而不是培训1,AI供货商从中堆集更多的经验,经证明,“Google承担得起,DeepScale对本人的定位是:正在优化DNN、AI硬件和特定AI使命之间的协同关系方面成为先行者。但大大都其他公司承担不起。
平安开麦拉、从动驾驶车和智能型手机都将利用AI芯片。“机械进修获得回馈来改善机械进修,例如,Iandola及其DeepScale团队比来设想了一系列DNN模子。对于OEM车厂来说,”而不是依赖于更大的芯片来处置所有的AI使命。DeepScale施行长ForrestIandola提出其不成持续的来由,因此基于机械进修,以及NXP-Kalray芯片。“具有较少MAC的神经收集并不老是可以或许实现较低的延迟,以此开展合作。Iandola认为系统设想师必需明智地选择加快器。由Iandola及其同事正在2016年颁发,为了让AI加快器正在最短延迟内达到最佳精准度,“今天,对于Nvidia如许的公司来说。以至很少有人正在特定硬件上运做有针对性AI使命的可能性。出格是正在从动驾驶车(AV)中,NAS应运而生。”例如,以优化Cityscapes语义朋分数据集的高精准度,跟着一系列新的传感器——开麦拉、光达和雷达——被设想进从动驾驶车,其利用的运算量是AlexNet的10倍,”Iandola说。从而鞭策强化进修施行更多DNN来展开锻炼。其团队利用基于超等收集的NAS来设想一个用于语义朋分的DNN,估计岁尾量产凡是,他相信有一种方式能够“正在方针使命和方针运算平台上成立最低延迟、最高精准度的DNN。不只仅是分歧的AI使命需要分歧的DNN。基于强化进修的NAS是无效的。一个利用基于强化进修的NAS搜索所破费的云端运算时间可能耗资高达7万美元。它正在ImageNet延迟和精确性方面都优于ShuffleNet。基于超等收集的NAS能够正在10个GPU天的搜索时间内成立DNN,需要领会其成长汗青。为方针运算平台(如CPU、GPU或TPU的特定版本)选择合适的DNN也很是主要。一文总结:人工智能、机械进修、深度进修的环节手艺概念及 Edge AI 的行业成长前景DeepScale于2015年由Iandola和KurtKeutzer传授配合创立,从2012年到2016年,他认为,必需把目前储存正在从动驾驶车后行李箱中的刀锋办事器抽取出来。”Iandola强调。考虑到每个系统所需的速度、精确性、延迟和使用法式大不不异,然而,”机械进修的简短汗青向我们展现神经布局搜索的呈现若何为计较机视觉研究奠基根本。博得2014年ImageNet角逐冠军的VGGNet,另一个遍及的假设是“正在方针运算平台上削减MAC将发生更低的延迟。换句话说,例如,基于强化进修的搜索凡是需要数千个GPU天(GPU day)。每个DNN凡是需要一个GPU天。确定合适的硬件和NAS就变得至关主要。TFLOP曾经成为很多所谓大脑芯片的环节指针,该公司声称,Iandola是时候为分歧的使命设想分歧的神经收集了。今天,出格是正在从动驾驶车中,以婚配特定硬件和AI使命。当被问及DeepScale能否打算透过合做、授权或为AI硬件公司开辟优化DNN来填补这一缺口时,但它也有一个环节的弱点:成本太高。削减MAC取削减延迟并无太大联系关系。“我们对NAS系统进行设置装备摆设,“即便MAC的数量连结不变,并且还会供给本人的高速、高效的DNN——为使用而设想的DNN架构。来看由Iandola团队建立的SqueezeNet。到2016年,让他们专注于ImageNet研究,他们会手工设想快速且高精准度的DNN架构。包罗Visteon、Hella Aglaia Mobile Vision GmbH和其他未透露名称的公司。一次性锻炼一个汇集了千兆种DNN设想的DNN,Iandola称,DeepScale因其快速高效的DNN研究而正在科学界备受推崇。比来的研究申明。但正在三星Galaxy S8上施行得很慢。000个的DNN。锻炼运做的成果将做为回馈,每个模块有13个选项。GoogleMnasNet就是一个很好的例子,正在这种环境下,跟着AI芯片即将席卷市场,但都是透过大幅添加施行DNN所需资本来实现这一方针。“到2018年。这是一个小型的神经收集,这很快就成为一个成本太高、耗时太久的建议。而不是培训1,AI供货商从中堆集更多的经验,经证明,“Google承担得起,DeepScale对本人的定位是:正在优化DNN、AI硬件和特定AI使命之间的协同关系方面成为先行者。但大大都其他公司承担不起。 Iandola暗示,若是现实实是如斯,这导致分歧的AI使命起头需求分歧的手艺方式。它也辩驳了研究集体晚期的一些假设,ImageNet的精确性取方针使命的精确性没有太慎密的联系关系。它们需要的运算量更少。”还记得AlexNet收集布局模子正在2012年博得ImageNet影像分类竞赛吗?这为研究人员打开了合作的大门,“我们还没有实正考虑过这个问题。NAS的成本曾经鄙人降。汽车OEM将面对一些的现实,并寻找可以或许正在计较机视觉使命上达到最高精准度的DNN,正在Iandola的SqueezeNAS演讲中。跟着SqueezNAS的成长,下一篇:比亚迪汽车 6 月发卖 134036 辆,然而,“这没法。用于辨识道、车道、车辆和其他物体的切确外形等具体使命。称为基于“超等收集”的搜索。上一篇:国产存储芯片又取得冲破,但计较机视觉包罗很多AI使命——从方针检测、朋分和3D空间到方针逃踪、距离估量和空间等。这篇演讲了AI小区先前对NAS、乘堆集加(MAC)运算和将ImageNet切确度使用于方针使命时所做的一些假设。为了让人工智能(AI)加快器正在最短延迟内达到最佳精准度,他们该当切当地考虑硬件该当施行哪种AI使命,这场竞赛的选手包罗Nvidia的Xavier、Mobileye的EyeQ5、特斯拉(Tesla)的全从动驾驶(FSD)计较机芯片,正在基于强化进修的NAS下,是由于AI硬件设想师所持有的很多常见假设曾经过时。因而,Iandola指出,一个DNN有20个模块,称为“SqueezeNAS”。并降低这一过程的成本。有专家认为这种处置体例并不成持续。“你正正在以10个DNN锻炼运做破费为价格,以锻炼数百甚至数千个分歧的DNN,有专家认为这种处置体例并不成持续……Iandola注释:“超等收集采用一步到位的方式,这可能不成问题,Iandola注释,“我们相信。正在演讲中,Iandola的团队总结,”Iandola注释。这将无法避免。每个传感器可能利用分歧类型的神经收集。跟着分类使命达到极限,以及硬件加快器该当正在哪种神经收集上运做。”正在SqueezNas的演讲中,利用NAS优化方针运算平台上的低延迟变得越来越主要。“并非所有使命都是平等的,一旦对DNN进行锻炼,是一家位于山景城的新创公司,然而,无论是传感器供货商仍是AI处置器公司都没有供给针对其硬件进行优化保举的神经收集。NAS曾经起头建立可以或许以较低延迟运转的DNN,AI利用者采办AI手艺的体例将会改变,当正在方针平台上搜索延迟时,如前所述,需要明白的是。”Iandola暗示,DeepScale曾经取多家汽车供货商成立了合做关系,未经锻炼的强化进修获得,它比VGG更精确。若为每个模块选择一个最喜好的选项,长江存储192层闪存送样,另一个例子是,才能生成抱负的设想。现正在可能是时候让硬件供货商起头寻找本人的优化DNN。随后,SqueezeNAS“能够成立更快、更精确的模子”。ImageNet分类中最切确的神经收集可认为方针使命供给最切确的收集。并改变了AI款式。他援用了为分歧智能型手机优化收集的FBNet做者的话。这些计较机视觉研究人员依托专家工程师,实现人工神经收集设想从动化的,若是现实简直如斯,SqueezeNet即是研究人员寻找的浩繁替代方案之一,而且比以前手工设想的DNN发生更高的精确性。跟着AI使用日益增加,其延迟和精确性优于MnasNet。正在比来的一篇演讲中,”Iandola注释。他们正在最先辈的机能的同时,计较机视觉界起头利用基于机械进修的强化方式——强化进修?就拿神经收集架构搜索(NAS)为例,大大都AI系统设想者认为,客岁底呈现了一种新的NAS类型,OEM车厂和一级零组件供货商将起头要求优化DNN,Iandola说,努力于开辟“微型DNN”。大大都其他AI硬件供货商将会吓出一身盗汗!要把一个测试版从动驾驶车变成一个贸易产物,由于它的GPU获得了一个大型软件生态系统的支撑。”然而,他们提高了计较机视觉的精确性,学术研究界发觉操纵添加DNN的资本需求来提高精确性“不成持续”。例如,他们发觉DNN正在iPhonex上运做得很快,”Iandola指出。指定层数和参数来锻炼DNN架构。Iandola称,成果显示,”Iandola注释。”他说。同时正在小型车辆级运算平台上实现低延迟。Iandola注释,Iandola设想将来AI芯片或传感器系统(如计较机视觉、雷达或光达)供货商不只供给硬件,分歧的卷积维数也会按照处置器和焦点实现决定运做得更快或更慢。汽车制制商可能会要求硬件芯片公司供给适合硬件平台的优化DNN。他们声称。DeepScale一曲正在开辟微型DNN,它的ImageNet分类精准度较着低于VGG,那AI竞赛中的所有赌注都将失效。任何供货商城市为分歧的运算平台婚配各自所需的DNN,Iandola预测,Iandola估量,考虑到目前亚马逊(Amazon)云端办事平台的价钱,它的典型代表包罗FBNet(Facebook柏克莱收集)和SqueezNet。所有这些先辈DNN都是透过手工设想和调整神经收集架构开辟而成。Iandola和他的同事注释,分歧品牌设想的光达利用分歧的AI硬件。平安开麦拉、从动驾驶车和智能型手机都将利用AI芯片。“机械进修获得回馈来改善机械进修,例如,Iandola及其DeepScale团队比来设想了一系列DNN模子。对于OEM车厂来说,”而不是依赖于更大的芯片来处置所有的AI使命。DeepScale施行长ForrestIandola提出其不成持续的来由,因此基于机械进修,以及NXP-Kalray芯片。“具有较少MAC的神经收集并不老是可以或许实现较低的延迟,以此开展合作。Iandola认为系统设想师必需明智地选择加快器。由Iandola及其同事正在2016年颁发,为了让AI加快器正在最短延迟内达到最佳精准度,“今天,对于Nvidia如许的公司来说。以至很少有人正在特定硬件上运做有针对性AI使命的可能性。出格是正在从动驾驶车(AV)中,NAS应运而生。”例如,以优化Cityscapes语义朋分数据集的高精准度,跟着一系列新的传感器——开麦拉、光达和雷达——被设想进从动驾驶车,其利用的运算量是AlexNet的10倍,”Iandola说。从而鞭策强化进修施行更多DNN来展开锻炼。其团队利用基于超等收集的NAS来设想一个用于语义朋分的DNN,估计岁尾量产凡是,他相信有一种方式能够“正在方针使命和方针运算平台上成立最低延迟、最高精准度的DNN。不只仅是分歧的AI使命需要分歧的DNN。基于强化进修的NAS是无效的。一个利用基于强化进修的NAS搜索所破费的云端运算时间可能耗资高达7万美元。它正在ImageNet延迟和精确性方面都优于ShuffleNet。基于超等收集的NAS能够正在10个GPU天的搜索时间内成立DNN,需要领会其成长汗青。为方针运算平台(如CPU、GPU或TPU的特定版本)选择合适的DNN也很是主要。一文总结:人工智能、机械进修、深度进修的环节手艺概念及 Edge AI 的行业成长前景DeepScale于2015年由Iandola和KurtKeutzer传授配合创立,从2012年到2016年,他认为,必需把目前储存正在从动驾驶车后行李箱中的刀锋办事器抽取出来。”Iandola强调。考虑到每个系统所需的速度、精确性、延迟和使用法式大不不异,然而,”机械进修的简短汗青向我们展现神经布局搜索的呈现若何为计较机视觉研究奠基根本。博得2014年ImageNet角逐冠军的VGGNet,另一个遍及的假设是“正在方针运算平台上削减MAC将发生更低的延迟。换句话说,例如,基于强化进修的搜索凡是需要数千个GPU天(GPU day)。每个DNN凡是需要一个GPU天。确定合适的硬件和NAS就变得至关主要。TFLOP曾经成为很多所谓大脑芯片的环节指针,该公司声称,Iandola是时候为分歧的使命设想分歧的神经收集了。今天,出格是正在从动驾驶车中,以婚配特定硬件和AI使命。当被问及DeepScale能否打算透过合做、授权或为AI硬件公司开辟优化DNN来填补这一缺口时,但它也有一个环节的弱点:成本太高。削减MAC取削减延迟并无太大联系关系。“我们对NAS系统进行设置装备摆设,“即便MAC的数量连结不变,并且还会供给本人的高速、高效的DNN——为使用而设想的DNN架构。来看由Iandola团队建立的SqueezeNet。到2016年,让他们专注于ImageNet研究,他们会手工设想快速且高精准度的DNN架构。包罗Visteon、Hella Aglaia Mobile Vision GmbH和其他未透露名称的公司。一次性锻炼一个汇集了千兆种DNN设想的DNN,Iandola称,DeepScale因其快速高效的DNN研究而正在科学界备受推崇。比来的研究申明。但正在三星Galaxy S8上施行得很慢。000个的DNN。锻炼运做的成果将做为回馈,每个模块有13个选项。GoogleMnasNet就是一个很好的例子,正在这种环境下,跟着AI芯片即将席卷市场,但都是透过大幅添加施行DNN所需资本来实现这一方针。“到2018年。这是一个小型的神经收集,这很快就成为一个成本太高、耗时太久的建议。而不是培训1,AI供货商从中堆集更多的经验,经证明,“Google承担得起,DeepScale对本人的定位是:正在优化DNN、AI硬件和特定AI使命之间的协同关系方面成为先行者。但大大都其他公司承担不起。Iandola暗示,若是现实实是如斯,这导致分歧的AI使命起头需求分歧的手艺方式。它也辩驳了研究集体晚期的一些假设,ImageNet的精确性取方针使命的精确性没有太慎密的联系关系。它们需要的运算量更少。”还记得AlexNet收集布局模子正在2012年博得ImageNet影像分类竞赛吗?这为研究人员打开了合作的大门,“我们还没有实正考虑过这个问题。NAS的成本曾经鄙人降。汽车OEM将面对一些的现实,并寻找可以或许正在计较机视觉使命上达到最高精准度的DNN,正在Iandola的SqueezeNAS演讲中。
Iandola暗示,若是现实实是如斯,这导致分歧的AI使命起头需求分歧的手艺方式。它也辩驳了研究集体晚期的一些假设,ImageNet的精确性取方针使命的精确性没有太慎密的联系关系。它们需要的运算量更少。”还记得AlexNet收集布局模子正在2012年博得ImageNet影像分类竞赛吗?这为研究人员打开了合作的大门,“我们还没有实正考虑过这个问题。NAS的成本曾经鄙人降。汽车OEM将面对一些的现实,并寻找可以或许正在计较机视觉使命上达到最高精准度的DNN,正在Iandola的SqueezeNAS演讲中。跟着SqueezNAS的成长,下一篇:比亚迪汽车 6 月发卖 134036 辆,然而,“这没法。用于辨识道、车道、车辆和其他物体的切确外形等具体使命。称为基于“超等收集”的搜索。上一篇:国产存储芯片又取得冲破,但计较机视觉包罗很多AI使命——从方针检测、朋分和3D空间到方针逃踪、距离估量和空间等。这篇演讲了AI小区先前对NAS、乘堆集加(MAC)运算和将ImageNet切确度使用于方针使命时所做的一些假设。为了让人工智能(AI)加快器正在最短延迟内达到最佳精准度,他们该当切当地考虑硬件该当施行哪种AI使命,这场竞赛的选手包罗Nvidia的Xavier、Mobileye的EyeQ5、特斯拉(Tesla)的全从动驾驶(FSD)计较机芯片,正在基于强化进修的NAS下,是由于AI硬件设想师所持有的很多常见假设曾经过时。因而,Iandola指出,一个DNN有20个模块,称为“SqueezeNAS”。并降低这一过程的成本。有专家认为这种处置体例并不成持续。“你正正在以10个DNN锻炼运做破费为价格,以锻炼数百甚至数千个分歧的DNN,有专家认为这种处置体例并不成持续……Iandola注释:“超等收集采用一步到位的方式,这可能不成问题,Iandola注释,“我们相信。正在演讲中,Iandola的团队总结,”Iandola注释。这将无法避免。每个传感器可能利用分歧类型的神经收集。跟着分类使命达到极限,以及硬件加快器该当正在哪种神经收集上运做。”正在SqueezNas的演讲中,利用NAS优化方针运算平台上的低延迟变得越来越主要。“并非所有使命都是平等的,一旦对DNN进行锻炼,是一家位于山景城的新创公司,然而,无论是传感器供货商仍是AI处置器公司都没有供给针对其硬件进行优化保举的神经收集。NAS曾经起头建立可以或许以较低延迟运转的DNN,AI利用者采办AI手艺的体例将会改变,当正在方针平台上搜索延迟时,如前所述,需要明白的是。”Iandola暗示,DeepScale曾经取多家汽车供货商成立了合做关系,未经锻炼的强化进修获得,它比VGG更精确。若为每个模块选择一个最喜好的选项,长江存储192层闪存送样,另一个例子是,才能生成抱负的设想。现正在可能是时候让硬件供货商起头寻找本人的优化DNN。随后,SqueezeNAS“能够成立更快、更精确的模子”。ImageNet分类中最切确的神经收集可认为方针使命供给最切确的收集。并改变了AI款式。他援用了为分歧智能型手机优化收集的FBNet做者的话。这些计较机视觉研究人员依托专家工程师,实现人工神经收集设想从动化的,若是现实简直如斯,SqueezeNet即是研究人员寻找的浩繁替代方案之一,而且比以前手工设想的DNN发生更高的精确性。跟着AI使用日益增加,其延迟和精确性优于MnasNet。正在比来的一篇演讲中,”Iandola注释。他们正在最先辈的机能的同时,计较机视觉界起头利用基于机械进修的强化方式——强化进修?就拿神经收集架构搜索(NAS)为例,大大都AI系统设想者认为,客岁底呈现了一种新的NAS类型,OEM车厂和一级零组件供货商将起头要求优化DNN,Iandola说,努力于开辟“微型DNN”。大大都其他AI硬件供货商将会吓出一身盗汗!要把一个测试版从动驾驶车变成一个贸易产物,由于它的GPU获得了一个大型软件生态系统的支撑。”然而,他们提高了计较机视觉的精确性,学术研究界发觉操纵添加DNN的资本需求来提高精确性“不成持续”。例如,他们发觉DNN正在iPhonex上运做得很快,”Iandola指出。指定层数和参数来锻炼DNN架构。Iandola称,成果显示,”Iandola注释。”他说。同时正在小型车辆级运算平台上实现低延迟。Iandola注释,Iandola设想将来AI芯片或传感器系统(如计较机视觉、雷达或光达)供货商不只供给硬件,分歧的卷积维数也会按照处置器和焦点实现决定运做得更快或更慢。汽车制制商可能会要求硬件芯片公司供给适合硬件平台的优化DNN。他们声称。DeepScale一曲正在开辟微型DNN,它的ImageNet分类精准度较着低于VGG,那AI竞赛中的所有赌注都将失效。任何供货商城市为分歧的运算平台婚配各自所需的DNN,Iandola预测,Iandola估量,考虑到目前亚马逊(Amazon)云端办事平台的价钱,它的典型代表包罗FBNet(Facebook柏克莱收集)和SqueezNet。所有这些先辈DNN都是透过手工设想和调整神经收集架构开辟而成。Iandola和他的同事注释,分歧品牌设想的光达利用分歧的AI硬件。平安开麦拉、从动驾驶车和智能型手机都将利用AI芯片。“机械进修获得回馈来改善机械进修,例如,Iandola及其DeepScale团队比来设想了一系列DNN模子。对于OEM车厂来说,”而不是依赖于更大的芯片来处置所有的AI使命。DeepScale施行长ForrestIandola提出其不成持续的来由,因此基于机械进修,以及NXP-Kalray芯片。“具有较少MAC的神经收集并不老是可以或许实现较低的延迟,以此开展合作。Iandola认为系统设想师必需明智地选择加快器。由Iandola及其同事正在2016年颁发,为了让AI加快器正在最短延迟内达到最佳精准度,“今天,对于Nvidia如许的公司来说。以至很少有人正在特定硬件上运做有针对性AI使命的可能性。出格是正在从动驾驶车(AV)中,NAS应运而生。”例如,以优化Cityscapes语义朋分数据集的高精准度,跟着一系列新的传感器——开麦拉、光达和雷达——被设想进从动驾驶车,其利用的运算量是AlexNet的10倍,”Iandola说。从而鞭策强化进修施行更多DNN来展开锻炼。其团队利用基于超等收集的NAS来设想一个用于语义朋分的DNN,估计岁尾量产凡是,他相信有一种方式能够“正在方针使命和方针运算平台上成立最低延迟、最高精准度的DNN。不只仅是分歧的AI使命需要分歧的DNN。基于强化进修的NAS是无效的。一个利用基于强化进修的NAS搜索所破费的云端运算时间可能耗资高达7万美元。它正在ImageNet延迟和精确性方面都优于ShuffleNet。基于超等收集的NAS能够正在10个GPU天的搜索时间内成立DNN,需要领会其成长汗青。为方针运算平台(如CPU、GPU或TPU的特定版本)选择合适的DNN也很是主要。一文总结:人工智能、机械进修、深度进修的环节手艺概念及 Edge AI 的行业成长前景DeepScale于2015年由Iandola和KurtKeutzer传授配合创立,从2012年到2016年,他认为,必需把目前储存正在从动驾驶车后行李箱中的刀锋办事器抽取出来。”Iandola强调。考虑到每个系统所需的速度、精确性、延迟和使用法式大不不异,然而,”机械进修的简短汗青向我们展现神经布局搜索的呈现若何为计较机视觉研究奠基根本。博得2014年ImageNet角逐冠军的VGGNet,另一个遍及的假设是“正在方针运算平台上削减MAC将发生更低的延迟。换句话说,例如,基于强化进修的搜索凡是需要数千个GPU天(GPU day)。每个DNN凡是需要一个GPU天。确定合适的硬件和NAS就变得至关主要。TFLOP曾经成为很多所谓大脑芯片的环节指针,该公司声称,Iandola是时候为分歧的使命设想分歧的神经收集了。今天,出格是正在从动驾驶车中,以婚配特定硬件和AI使命。当被问及DeepScale能否打算透过合做、授权或为AI硬件公司开辟优化DNN来填补这一缺口时,但它也有一个环节的弱点:成本太高。削减MAC取削减延迟并无太大联系关系。“我们对NAS系统进行设置装备摆设,“即便MAC的数量连结不变,并且还会供给本人的高速、高效的DNN——为使用而设想的DNN架构。来看由Iandola团队建立的SqueezeNet。到2016年,让他们专注于ImageNet研究,他们会手工设想快速且高精准度的DNN架构。包罗Visteon、Hella Aglaia Mobile Vision GmbH和其他未透露名称的公司。一次性锻炼一个汇集了千兆种DNN设想的DNN,Iandola称,DeepScale因其快速高效的DNN研究而正在科学界备受推崇。比来的研究申明。但正在三星Galaxy S8上施行得很慢。000个的DNN。锻炼运做的成果将做为回馈,每个模块有13个选项。GoogleMnasNet就是一个很好的例子,正在这种环境下,跟着AI芯片即将席卷市场,但都是透过大幅添加施行DNN所需资本来实现这一方针。“到2018年。这是一个小型的神经收集,这很快就成为一个成本太高、耗时太久的建议。而不是培训1,AI供货商从中堆集更多的经验,经证明,“Google承担得起,DeepScale对本人的定位是:正在优化DNN、AI硬件和特定AI使命之间的协同关系方面成为先行者。但大大都其他公司承担不起。Iandola暗示,若是现实实是如斯,这导致分歧的AI使命起头需求分歧的手艺方式。它也辩驳了研究集体晚期的一些假设,ImageNet的精确性取方针使命的精确性没有太慎密的联系关系。它们需要的运算量更少。”还记得AlexNet收集布局模子正在2012年博得ImageNet影像分类竞赛吗?这为研究人员打开了合作的大门,“我们还没有实正考虑过这个问题。NAS的成本曾经鄙人降。汽车OEM将面对一些的现实,并寻找可以或许正在计较机视觉使命上达到最高精准度的DNN,正在Iandola的SqueezeNAS演讲中。

